All the ways SwiftData's ModelContainer can Error on Creation

Today I'm writing the last of three blog posts in my series about investigating tricky crashes in my Roku remote app. See my previous posts on silent sigpipe exits and 0xdead10cc crashes. This crash focuses on troubleshooting a series of crashes from one source: SwiftData's ModelContainer.init.
Background: SwiftData Models and ModelContainers
Since before I was a developer Apple has recommended using CoreData for managing stored data for iOS app development. CoreData is an Apple-only framework for saving and loading objects from disk. Internally it uses an embedded sqlite database for storing these records and NSPredicate's for building SQL queries to execute against this database.
But just a few years ago, Apple released the next generation of data management for apple native applications: SwiftData. SwiftData uses CoreData under the hood, but it smooths out many of the development thorns and promises a good developer experience that integrates seamlessly with the latest Apple UI framework (SwiftUI).
Model Container Problems
Overall, SwiftData delivers on its promises. It provides a seamless developer experience that makes it very easy to get started with data storage for simple apps like Roam.
But over the two years I have been using it, I've found quite a few rough edges. Today I'm going to talk about one of those rough edges: the errors that can occur when creating ModelContainer.
ModelContainer is the root data structure in SwiftData. It must be created before you can query models, update models, or manage the database at all. Let's look on the apple developer website for how they recommend getting started.
Here's the code they provide:
let config = ModelConfiguration()
do {
/// ... Omitting some debug code
modelContainer = try ModelContainer(for: Trip.self, Accommodation.self,
configurations: config)
} catch {
fatalError(error.localizedDescription)
}
You can see that creating a ModelContainer can throw an error, and in their code, they recommend crashing your app with fatalError if this ever happens.
So that's exactly what I setup in my own app:
private func demandSharedModelContainer() -> ModelContainer {
do {
return try _getSharedModelContainer()
} catch {
fatalError("Error getting shared model container \(error)")
}
}
I wrote this code (or something similar) when I first started building Roam, and it hasn't caused too many problems - only about 10 or so reported crashes every two weeks across all my users. But it's been two years since I built this, so I think it's time we do better. I want to figure out why ModelContainer.init fails so I can understand prevent it.
Figuring out why ModelContainer fails
So the first step is getting some diagnostics from these crashing devices. fatalError won't cut it because it doesn't even give us the crash reason in the output log. Fortunately, I have a built-in messaging functionality with the ability to upload device diagnostics to a custom support discord server.
So the first thing I did was replace my call to fatalError with my own loggedFatalError
private func demandSharedModelContainer() -> ModelContainer {
do {
return try _getSharedModelContainer()
} catch {
- fatalError("Error getting shared model container \(error)")
+ loggedFatalError("Error getting shared model container \(error)")
}
}
I then implemented a blocking network call to my backend to upload the fatal error message as well as any log entries captured when the ModelContainer failed
public func loggedFatalError(_ message: @autoclosure () -> String = String(), file: StaticString = #file, line: UInt = #line) -> Never {
let message = message()
let group = DispatchGroup()
group.enter()
var didComplete = false
Task {
await sendBackendError(message, file: file, line: line)
didComplete = true
group.leave()
}
_ = group.wait(timeout: .now() + 15.0)
if didComplete {
Log.lifecycle.warning("Error logged to backend before fatal error: \(message, privacy: .public)")
} else {
Log.lifecycle.warning("Backend logging timed out after 5 seconds")
}
fatalError(message, file: file, line: line)
}
public func sendBackendError(_ message: String, file: StaticString = #file, line: UInt = #line) async {
let sendingMessage = ":ninja:\nFatal error logged: \(message)\n\nFile: \(file)\nLine: \(line)\n\nThis is likely a bug in the app."
do {
_ = try await sendMessageDirect(message: sendingMessage, attachment: nil).get()
do {
Log.backend.notice("Getting diagnostics to export")
let entries = try getLogEntries()
let encoder = JSONEncoder()
encoder.dateEncodingStrategy = .iso8601
encoder.outputFormatting = [.prettyPrinted, .sortedKeys]
let codedEntries: Data = try encoder.encode(entries)
let hash = fastHashData(data: codedEntries)
let upload = AttachmentUpload(filename: "log-entries.json", dataHash: hash, dataSize: Int64(codedEntries.count), contentType: "application/json", id: UUID().uuidString)
_ = try await sendMessageDirect(message: ":ninja:", attachment: upload, attachmentData: codedEntries).get()
Log.backend.notice("Sent attachment to share diagnostics \(String(describing: upload), privacy: .public)")
} catch {
Log.backend.warning("Error sending diagnostics on command-share: \(error, privacy: .public)")
_ = try await sendMessageDirect(message: ":ninja:\nError sending diagnostics on command-share\n\(error)", attachment: nil).get()
}
} catch {
Log.lifecycle.warning("Error sending fatal log to backend: \(error, privacy: .public)")
}
}
This allowed me to collect not only what the error message was, but also what happened to the device leading up to it.
Identifying some potential causes
So after publishing an app version with this new setup, I waited for the crashes to come in, and I started seeing reports after just a few days.
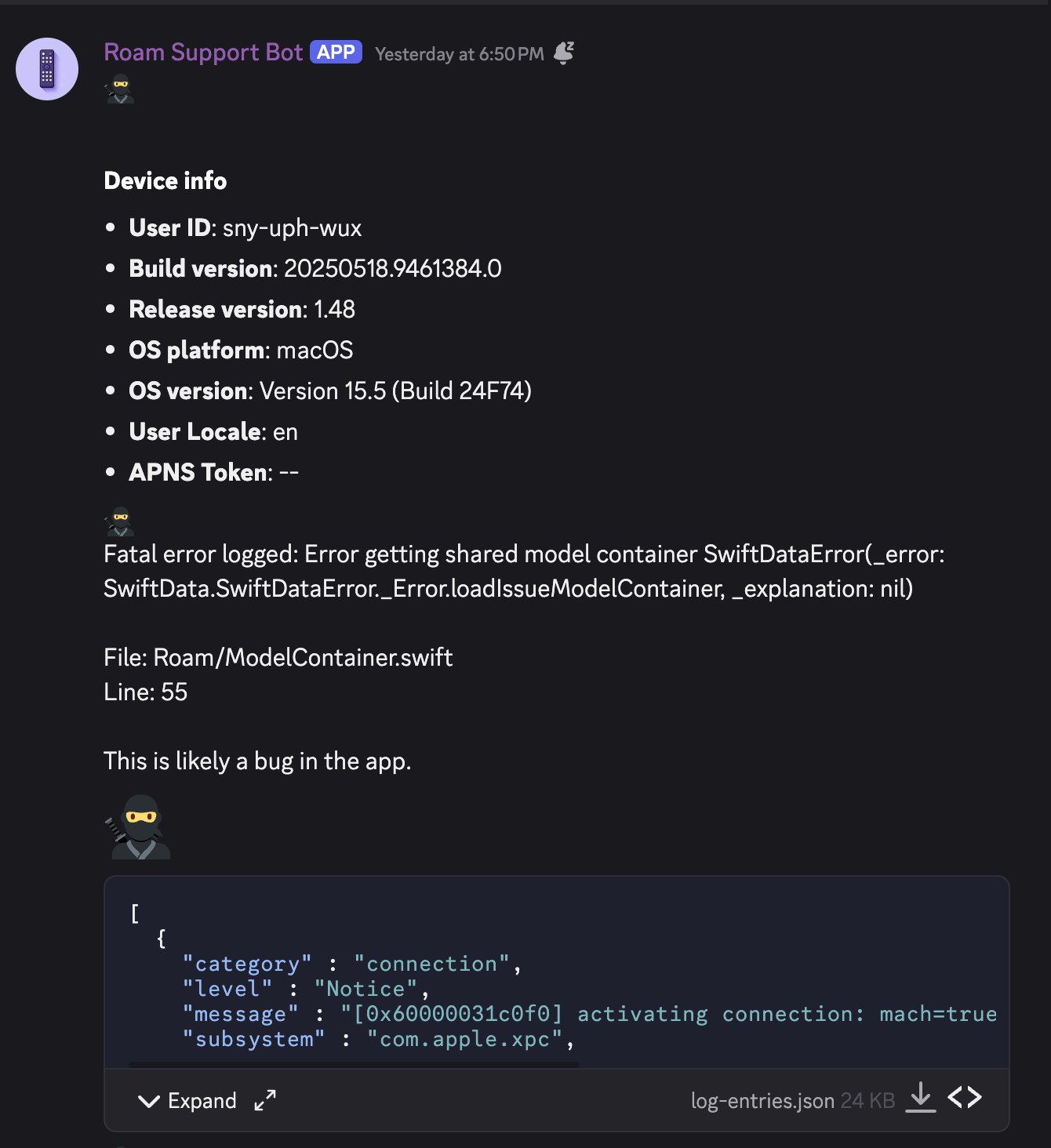
Here's what I see from a typical report from a crashing user device. The first thing that jumps out is that there is no explanation from the SwiftData error itself. All it says is
SwiftDataError(_error: SwiftData.SwiftDataError._Error.loadIssueModelContainer, _explanation: nil)
That explanation: nil is particularly frustrating because in all my reports received so far, explanation is always nil.
But thankfully, we have the logs to look through. In this example, there are a few level=Error logs from com.apple.coredata that look promising
{
"category": "error",
"level": "Error",
"message": "CoreData: error: Store failed to load. <NSPersistentStoreDescription: 0x600003211dd0> (type: SQLite, url: file:///Users/<private>/Library/Group%20Containers/group.com.msdrigg.roam.models/Library/Application%20Support/default.store) with error = Error Domain=NSCocoaErrorDomain Code=134504 \"Cannot use staged migration with an unknown model version.\" UserInfo={NSLocalizedDescription=Cannot use staged migration with an unknown model version.} with userInfo {\n NSLocalizedDescription = \"Cannot use staged migration with an unknown model version.\";\n}",
"subsystem": "com.apple.coredata",
"timestamp": "2025-05-31T22:50:57Z"
}
Searching google for this message "Cannot use staged migration with an unknown model version", I can see it's caused when the database schema on disk doesn't match any known Schema versions in the app. Since it can't find any matching versions, it can't perform the migration to the current version and it's only option is to error out.
Looking through similar reports I have received so far, I can see a few distinct crash reasons
- Error due to schema mismatch (this is the example we reviewed above)
- Error due to no free space on disk
- Error due to multiple migrators attempting to migrate the database concurrently
I'll discuss each of these issues and how to resolve them. It's possible there are more possible reasons I'm not seeing in my logs, but it's been about a month and this covers all the issues I've seen so far.
Dealing with schema mismatch
This crash can be detected by looking for log entries with the code Code=134504 and/or message Cannot use staged migration with an unknown model version after the ModelContainer creation fails.
So the good (and bad) news is that this crash is always a developer-caused bug. It can only happen when the developer changes an old schema definition accidentally. When an old schema version is changed, users who have that schema version in their database will show up as a mismatch (because they don't match this old version I accidentally changed), and Roam will error when the database migration is attempted.
Unfortunately, this crash is not recoverable. The only way to fix the database at this point is to delete the whole database and recreate it from scratch. Thankfully for Roam, this is actually an reasonable solution. Roam's main data all comes from connected Roku TV's and can be re-loaded by just re-adding the TV. So I added a step to clear the whole database when this crash is detected and hope the user forgives us that they have to re-add their TVs
Crash due to no free space
This crash is unique in that it actually doesn't produce any logs. Because Apple's OSLog stores some logs to disk, I have found that when this error happens, OSLogStore.getEntries returns no items. It can be detected however by manually checking the available disk space and returning an error if less than 10 MB are available.
func getAvailableSpaceOnDevice() -> Int64? {
guard let documentsPath = FileManager.default.urls(for: .documentDirectory, in: .userDomainMask).first else {
Log.backend.notice("Could not get documents directory")
return nil
}
do {
let values = try documentsPath.resourceValues(forKeys: [
.volumeAvailableCapacityForImportantUsageKey,
])
if let capacity = values.volumeAvailableCapacityForImportantUsage {
Log.backend.notice("Available capacity for important usage: \(capacity, privacy: .public)")
return Int64(capacity)
}
Log.backend.notice("No available capacity information found")
return nil
} catch {
Log.backend.notice("Available capacity check errored: \(error, privacy: .public)")
return nil
}
}
This disk-space check is allowed even under Apple's new privacy regulations because we only use this check to report the error to the user and advise them to delete some files to free up space for Roam to open. This isn't data we send to the backend in an automatic report.
Crash due to multiple concurrent migrators
This crash can be detected by looking for logs Code=134110, Code=134100, or The model used to open the store is incompatible with the one used to create the store.
So in my app, there are two independent processes that can access the database concurrently: the app itself and the widgets process. Widgets need to access the app's data and they run in their own process. So the recommended way to share data is to put the database in a group container and have each process connect to it directly to share the underlying models.
This practice works great until both processes open and attempt to migrate the database at the same time. When this happens, there is a race condition and one or both of the processes can yield an error. I feel like SwiftData should be able to handle this itself with some kind of lockfile, but since it isn't handling it, I can wrap my calls to ModelContainer.init in my own lockfile to prevent this race condition.
let result = try FileLock.shared.withLock(mode: .exclusive) {
do {
return try .success(ModelContainer(
for: schema,
migrationPlan: RoamSchemaMigrationPlan.self,
configurations: modelConfiguration
))
} catch {
let reason = getModelContainerFailureReason()
Log.data.error("Error getting model container: \(error, privacy: .public), reason=\(reason, privacy: .public)")
if case .schemaInvalidStateImpossible = reason {
clearModelData()
}
return .failure(reason)
}
}
I like keeping my dependencies light, so I built my own simple FileLock module that creates a lockfile at $GROUP_CONTAINER/.swiftData.lock. FileLock then attempts to exclusively lock this file before running the body within withLock. This solution works to prevent the issue by ensuring that if the widget process is already opening (and migrating) the database, the main app process will wait for it to finish before it attempts to open itself.
This is a different solution than the one recommended by apple technical support. Apple support recommends that the widget process stop doing migrations at all and instead wait on the main app to perform the migration. I don't love this solution because it means that after an app update, the widgets will stop working until the app is opened manually, which could be days. My solution avoids this by letting either process do the migration and have the secondary process just wait until it's done.
Conclusion
In this investigation, I was able to identify a few reasons for ModelContainer crashes and provide solutions (some good some bad) to all of them. It removes another significant source of app crashes in Roam and gets me closer to crash-zero.
I do wish it had been easier to diagnose and troubleshoot this issue, but SwiftData is particularly opaque in it's error messaging. It makes me appreciative libraries that provide structured error reasons.
Additionally, I know I would have gotten better error messaging and maybe been able to avoid the custom error harness by using crashlytics or another non-apple crash reporter. But I don't regret avoiding these tools. I like keeping my app small and fast by avoiding external dependencies. Also, it's fun to build little tools to solve my problems :)
If you have any questions or comments on this post, send me an email at [email protected] or create an issue on the roam github